
|
3.3.6. Поиск информации в Интернет
ADO в Delphi AJAX Android C++ CakePHP CMS COM CSS Delphi Flash Flex HTML Internet Java JavaScript MySQL PHP RIA SCORM Silverlight SQL UML XML Бази даних Веб-розробка Генетичні алгоритми ГІС Гітара Дизайн Економіка Інтелектуальні СДН Колір Масаж Математика Медицина Музика Нечітка логіка ООП Патерни Подання знань Розкрутка сайту, SEO САПР Сесії в PHP Системне програмування Системний аналіз Тестологія Тестування ПЗ Фреймворки Штучний інтелект
|
Знання
→
Дистанційне навчання — теорія і практика
→
Разработка компьютерных средств обучения
→
3. Сетевые технологии в обучении
→
3.3 Организация сетевого общения
 Дистанційне навчання — теорія і практика → Разработка компьютерных средств обучения. Учебное пособие → 3. Сетевые технологии в обучении → 3.3 Организация сетевого общения Дистанційне навчання — теорія і практика → Разработка компьютерных средств обучения. Учебное пособие → 3. Сетевые технологии в обучении → 3.3 Организация сетевого общения3.3.6. Поиск информации в ИнтернетИнтернет является глобальным хранилищем информации, там, как и в Греции, можно найти все что угодно, нужно только знать, как и где искать, а также разумно относиться к найденной информации. Поясним сначала второй тезис. Со времени изобретения книгопечатания люди в основном читали, а не издавали информацию из-за дороговизны бумаги, подготовки и распространения печатных изданий. Одним из следствий этого является тщательность, с которой осуществляется печатная подготовка изданий. Достаточно сказать, что любой информационный материал перед изданием читают рецензенты, редакторы, наконец, корректоры. И, тем не менее, в публикациях встречаются ошибки фактографические (чаще всего намеренные), орфографические и синтаксические… С появлением Интернет и в особенности Всемирной паутины человек читающий стал человеком пишущим и публикующим. Если раньше перед рукописью стояли многочисленные барьеры, которые преодолевали не проценты, а даже доли процентов авторов, то теперь сказать о себе городу и миру, как говорили древние римляне, может любой и каждый. Достаточно иметь рукопись и разместить ее на одном из web-серверов… В связи с этим рукописи публикуются, редко читаются и почти никогда не рецензируются. В Сети можно найти совершенно безграмотные публикации с орфографическими ошибками на каждой странице, изобилующие, скажем так, достаточно странными идеями и ненормативной лексикой.
На заметку
По образному выражению Интернет – это большая помойка и к найденной в Интернет информации необходимо относиться осторожно. Вывод из сказанного выше простой – ни в коем случае не доверяйте единственному источнику информации. Благо информации в Сети много, анализируйте, проверяйте и сопоставляйте информацию из различных источников, пытайтесь по имеющимся данным и гиперссылкам установить первоисточник информации. Теперь займемся вопросом, как искать информацию. В Интернет имеется достаточно большое число так называемых поисковых серверов, которые собирают и каталогизируют информацию из Всемирной паутины и других источников (архивов групп новостей, FTP-серверов и т.д.). Для поиска русскоязычной информации в настоящее время наиболее популярными являются поисковые сервера:
Советы
Технически поиск информации с помощью поискового сервера прост: наберите в адресной строке унифицированный указатель сервера, появится форма поиска (рис. 3.4), наберите в ней ключевые слова.
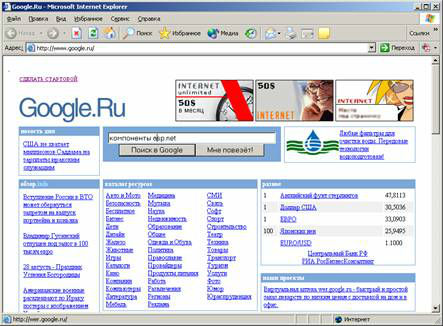 Рис. 3.4. Форма для ввода ключевых слов поискового сервера Google В данном случае нас интересовали программные компоненты для технологии Microsoft Asp.Net, поэтому в форме было введено компоненты asp.net. Дальше нужно нажать кнопку Поиск в Google, обеспечивающую передачу ключевых слов серверу. Сервер вернет ссылки на страницы, содержащие ключевые слова компоненты, а также asp.net, как показано на рис. 3.5.
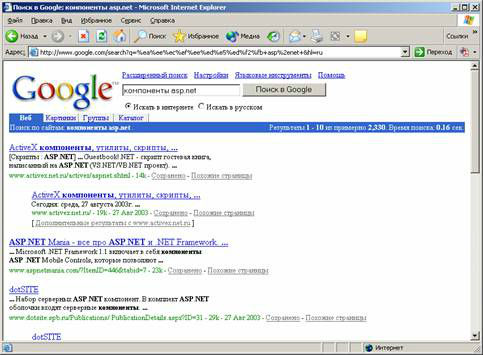 Рис.3.5. Результаты поиска В нашем случае Google вернул первые десять ссылок из 2330 имеющихся в базе данных. Это, пожалуй, слишком много, поэтому ограничимся просмотром первых десяти ссылок. Google упорядочил их для нас так, чтобы наиболее полезные ссылки шли первыми (возможно, что у нас и у Google определения полезности несколько разные). Отметим, что ссылки сопровождаются краткими аннотациями, которые в большинстве случаев помогает принять решение о том, просматривать ли страницу или ограничиться чтением комментария. Для перехода к найденной странице достаточно щелкнуть на заголовке, например, для первой ссылке на рис. 3.5 достаточно щелкнуть мышью на подчеркнутом тексте ActiveX компоненты, утилиты, скрипты…
Можно уменьшить число ссылок, возвращаемых сервером, уточнив, что же нам нужно. В данном примере кроме информации о компонентах Asp.Net было бы желательно получить их, поэтому уточним запрос, введя загрузить компоненты asp.net.
На заметку Вернемся к рис. 3.4. Наряду с поиском по ключевым словам большинство поисковых серверов предоставляют возможность поиска с помощью индексов – иерархических указателей. Выбрав интересующую тему, например, Образование, щелкните мышью, и так постепенно уточняя запрос, можно добраться до ссылок на интересующую Вас информацию. Как поисковые сервера ищут информацию в Интернет ?
Выше мы рассматривали поиск в Интернет с непосредственным использованием поисковых серверов. В настоящее время популярность приобретает программное обеспечение, устанавливаемое на компьютере пользователя и облегчающее поиск информации, по крайней мере, в двух направлениях: введенный запрос на поиск передается не одному, а нескольким поисковым серверам, программа также облегчает хранение, анализ и классификацию. В качестве примеров таких программ можно привести Copernic Agent или отечественный ДИСКо Искатель. Кроме поисковых серверов общего назначения в Интернет имеются специализированные поисковые серверы, например, для поиска рефератов (http://www.referat.ru), поиска товаров и сравнения цен (http://www.price.ru). Отметим также, что поиск в Интернет требует терпения и навыков, приобретаемых при проведении поиска, поэтому не ленитесь и экспериментируйте! Зверніть увагу на додаткові посиланняГоловний розділСторінки, близькі за змістомзагрузка...
|
Сторінки, близькі за змістом
|
|
Copyright © 2008—2026 Портал Знань.
При використанні матеріалів посилання, для інтернет-ресурсів — гіперпосилання, на Znannya.org обов'язкове.
Зв'язок
|
НТУУ "КПІ" Інженерія програмного забезпечення КПІ Лабораторія СЕТ |
|

