
|
Text Mining
ADO в Delphi AJAX Android C++ CakePHP CMS COM CSS Delphi Flash Flex HTML Internet Java JavaScript MySQL PHP RIA SCORM Silverlight SQL UML XML Бази даних Веб-розробка Генетичні алгоритми ГІС Гітара Дизайн Економіка Інтелектуальні СДН Колір Масаж Математика Медицина Музика Нечітка логіка ООП Патерни Подання знань Розкрутка сайту, SEO САПР Сесії в PHP Системне програмування Системний аналіз Тестологія Тестування ПЗ Фреймворки Штучний інтелект
|
Text MiningText Mining — это набор технологий и методов, предназначенных для извлечения информации из текстов. Основная цель - дать аналитику возможность работать с большими объемами исходных данных за счет автоматизации процесса извлечения нужной информации.
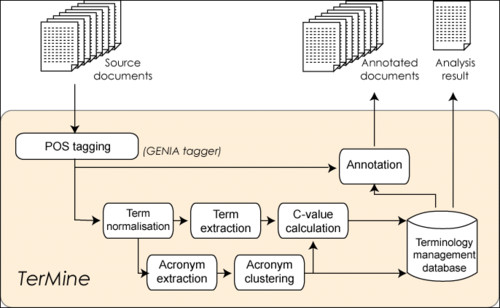
 Основные задачи Text MiningКак и большинство когнитивных технологий, Text Mining – это алгоритмическое выявление прежде не известных связей и корреляций в уже имеющихся текстовых данных. Важная задача технологии Text Mining связана с извлечением из текста его характерных элементов или свойств, которые могут использоваться как метаданные документа, ключевых слов, аннотаций. Другая важная задача состоит в отнесении документа к некоторым категориям из заданной схемы их систематизации. Text Mining также обеспечивает новый уровень семантического поиска документов. Возможности современных систем Text Mining могут применяться при управлении знаниями для выявления шаблонов в тексте, для автоматического «выталкивания» или размещения информации по интересующим пользователей профилям, создавать обзоры документов. Основные элементы Text MiningВ соответствии с уже сформированной методологии к основным элементам Text Mining относятся:
Также в некоторых случаях набор дополняют средства поддержки и создание таксономии (oftaxonomies) и тезаурусов (thesauri).
По материалам сайта: Зверніть увагу на додаткові посиланняГоловний розділСторінки, близькі за змістомзагрузка...
|
Сторінки, близькі за змістом
|
|
Copyright © 2008—2026 Портал Знань.
При використанні матеріалів посилання, для інтернет-ресурсів — гіперпосилання, на Znannya.org обов'язкове.
Зв'язок
|
НТУУ "КПІ" Інженерія програмного забезпечення КПІ Лабораторія СЕТ |
|
 Керування знаннями
Керування знаннями

