
|
Web Mining: интеллектуальный анализ данных в сети Internet
ADO в Delphi AJAX Android C++ CakePHP CMS COM CSS Delphi Flash Flex HTML Internet Java JavaScript MySQL PHP RIA SCORM Silverlight SQL UML XML Бази даних Веб-розробка Генетичні алгоритми ГІС Гітара Дизайн Економіка Інтелектуальні СДН Колір Масаж Математика Медицина Музика Нечітка логіка ООП Патерни Подання знань Розкрутка сайту, SEO САПР Сесії в PHP Системне програмування Системний аналіз Тестологія Тестування ПЗ Фреймворки Штучний інтелект
|
Web Mining: интеллектуальный анализ данных в сети InternetОглавление
1. Введение
5.1 Анализ использования веб-ресурсов 6. Методы Web Mining с точки зрения решаемых задач и реализуемых подходов
6.1 Поиск информации 7. Список источников информации ВведениеWeb Mining можно перевести как "добыча данных в Web". Web Intelligence или Web-Интеллект готов "открыть новую главу" в стремительном развитии электронного бизнеса. Способность определять интересы и предпочтения каждого посетителя, наблюдая за его поведением, является серьезным и критичным преимуществом конкурентной борьбы на рынке электронной коммерции. Системы Web Mining могут ответить на многие вопросы, например, кто из посетителей является потенциальным клиентом Web-магазина, какая группа клиентов Web-магазина приносит наибольший доход, каковы интересы определенного посетителя или группы посетителей. Технология Web Mining охватывает методы, которые способны на основе данных сайта обнаружить новые, ранее неизвестные знания и которые в дальнейшем можно будет использовать на практике. Другими словами, технология Web Mining применяет технологию Data Mining для анализа неструктурированной, неоднородной, распределенной и значительной по объему информации, содержащейся на Web-узлах. Чтобы лучше понять предметную область, рассмотрим основные понятия и принципы сети Интернет. Основные понятия и принципыВ таблице 1 приведено описание основных терминов и понятий, которые используются в данной статье. Таблица 1. Основные термины и понятия
Все сайты сети Интернет хранятся на веб-серверах. Чтобы получить страницу сайта, браузер посылает запросы на веб-сервер. В ответ на них возвращаются файлы, необходимые для формирования интернет-страницы в окне браузера. Эта идея наглядно продемонстрирована на рисунке 1.
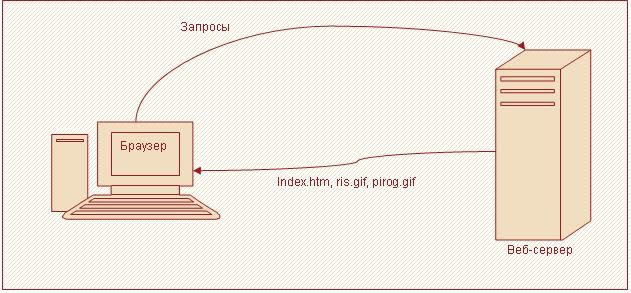 Рисунок 1. Взаимодействие браузера и веб-сервера Загрузив страницу, пользователь просматривает имеющуюся на ней информацию. После чего он может перейти на другую согласно структуре сайта, связи в которой устанавливаются посредством гиперссылок. Для удобства навигации страницы могут быть объединены в категории, а они в свою очередь в разделы. Подобная структура изображена на рисунке 2.
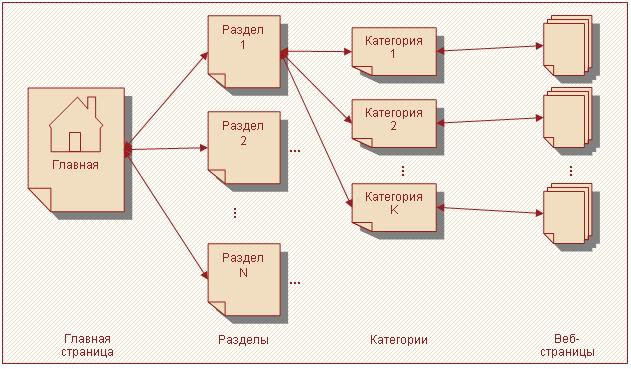 Рисунок 2. Пример структуры веб-сайта Внутри категорий между страницами может быть разнообразная структура (иерархическая, последовательная, сетевая). На большинстве сайтов предусмотрен быстрый переход с любой страницы на главную. В зависимости от выбранной структуры пользователь перемещается с одной страницы на другую. На рисунке 3 изображен фрагмент структуры сайта, где страницы пронумерованы согласно порядку их просмотра.
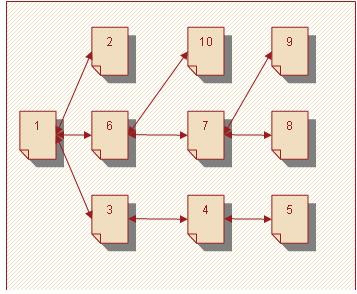 Рисунок 3 – Путь пользователя на сайте Можно заметить, что между пятой и шестой просматриваемыми страницами прямой ссылки нет, но исходя из структуры совершенно очевидно, что после пятой страницы пользователь вернулся к первой. Отсюда полный его путь по сайту будет следующим: 1, 2, 1, 3, 4, 5, 4, 3, 1, 6, 7, 8, 7, 9, 7, 6, 10. Исходя из перечисленных особенностей размещения информации в сети Интернет возникают различные сложности анализа веб-данных. Сложности анализа данных из сети ИнтернетВсемирная сеть сейчас содержит огромное количество информации, знаний. Пользователи на различных условиях могут просматривать всевозможные документы, аудио- и видеофайлы. Однако это многообразие данных скрывает в себе проблемы, которые могут возникнуть не только при анализе, но и при поиске необходимой информации в Интернет.
Обозначив сложности анализа веб-данных, вернемся к Web Mining. Рассмотрим его основные этапы. Этапы Web MiningВ Web Mining можно выделить следующие этапы:
Это общие шаги, которые необходимо пройти для анализа данных сети Интернет. Конкретные процедуры каждого этапа зависят от поставленной задачи. В связи с этом выделяют различные категории Web Mining. Категории Web Mining
Анализ использования веб-ресурсов
Это направление основано на извлечении данных из логов веб-серверов. Целью анализа является выявление предпочтений посетителей при использовании тех или иных ресурсов сети Интернет. Web Usage Mining включает следующие составляющие:
Каждый пользователь сети имеет свои индивидуальные вкусы, взгляды, в зависимости от которых он посещает те или иные ресурсы. Выявив, какие страницы и в какой последовательности открывал пользователь, можно сделать вывод о его предпочтениях. Анализ общих тенденции среди всех посетителей показывает, насколько эффективно работает электронный портал, какие его страницы посещаются больше всего, какие меньше. На основе этого анализа можно оптимизировать сайт: найти ранее не замеченные проблемы в функционировании, дизайне и др. Это направление Web Mining временами еще называют анализом потоков кликов (click stream analysis) – упорядоченное множество посещений страниц, которые просмотрел пользователь, попав на веб-сайт. Необходимые для анализа данные находятся в логах серверов и cookie-файлах. При загрузке веб-страницы браузер также запрашивает все вставленные в неё объекты, например графические файлы. В связи с этим возникает проблема с тем, что сервер добавляет в журнал записи о каждом таком запросе. Отсюда вытекает необходимость предобработки данных. После того как выделены отдельные просмотры страниц пользователем, их объединяют в сессию. Как только данные были очищены и подготовлены для анализа, необходимо задаться следующими вопросами: Какая страница является общей точкой входа для пользователей?
Лог-файлы веб-серверовПрежде чем приступить непосредственно к анализу потоков кликов, необходимо разобраться с типами доступных данных. Для этого рассмотрим файлы журнала веб-сервера – веб-логи. Для каждого запроса браузера к веб-серверу отклик генерируется автоматически, и все сведения заносятся в веб-лог – текстовый файл с разделителями в кодировке ASCII. Существуют различные форматы журналов веб-серверов. Главное их отличие заключается в количестве полей. Некоторые из них есть в логе любого формата. Опишем поля, которые являются общими для всех логов. Поле "удаленный хост". Это поле веб-лога содержит IP-адрес удаленного хоста, создавшего запрос, например "145.243.2.170". Если доступно имя удаленного хоста, то он может быть таким: "whgj3-45.gate.com". Его предпочтительнее использовать, чем IP-адрес, потому как оно может нести в себе ещё и семантический смысл. Поле "дата/время". В веб-логах может использоваться формат даты-времени в виде "ДД:ЧЧ:ММ:СС", где ДД – это число месяца, ЧЧ:ММ:СС отражает время. Также встречается и более общий формат: "ДД/Мес/ГГГГ:ЧЧ:ММ:СС смещение", где смещение – положительная или отрицательная константа, определяющая часовой пояс относительно GTM (среднего времени по Гринвичу). Например, "09/Jun/1988:03:27:00 -0500" – 3 часа 27 минут 9 июня 1988 года, время сервера на 5 часов позади GTM. Поле "HTTP запроса". В поле содержится информация о том, что клиентский браузер запросил с веб-сервера, и в нем могут быть выделены четыре части:
Чаще всего встречается метод GET, который используется для запроса содержимого указанного ресурса. Помимо этого могут быть и другие методы: HEAD, PUT, POST. Унифицированный индикатор ресурса содержит имя страницы/документа и путь к ней/нему. Эта информация может быть использована в анализе частоты посещений для страниц или файлов. Заголовок предоставляет дополнительную информацию о запросе браузера. С помощью него можно определить, например, какие ключевые слова использует пользователь в поисковой машине сайта. Далее указано наименование протокола и его версия. Поле кода состояния. Не всегда запросы браузеров заканчиваются успешным исходом. Поле кода состояния содержит трехзначное число, обозначающее исход запроса страницы браузером: удачный или неудачный. Успешной загрузке страницы соответствует код формата "2хх", а "4хх" – ошибке загрузки. Рассмотрим наиболее часто встречающиеся форматы веб-логов, которые зависят от конфигурации сервера. Common log format (CLF)Формат CLF поддерживается различными серверными приложениями и включает следующие семь полей:
Поле идентификации используется для хранения одинаковой информации, переданной клиентом в случае, если сервер выполняет соответствующую проверку. Оно обычно содержит прочерк, означающий, что информация об идентификации отсутствует. Если зарегистрированный пользователь посещал сайт, то его имя заносится в поле "аутентификация". В остальных случаях ставится прочерк. Extended common log format (ECLF)ECLF – это расширенный вариант формата CLF, полученный добавлением в запись журнала двух полей: направление и пользовательский агент. Поле "Направление". Это поле содержит URL предыдущего сайта, с которого был перенаправлен клиент. Для файлов, которые загружаются вместе со страницей, этот адрес совпадает с адресом страницы. Здесь содержится важная информация о том, как и откуда пользователи попадают на портал. Поле "Пользовательский агент". Здесь сосредоточена информация о клиентском браузере и его версии, об операционной системе посетителя. Важно заметить, что данное поле позволяет вычислить ботов. Веб-разработчики могут использовать это для блокировки определенной части электронного портала от подобных программ в целях равномерного распределения нагрузки на сайт. Аналитик по этому полю может отфильтровать данные, оставив только те запаси, которые отражают деятельность реальных посетителей. Пример записи веб-лога Рассмотрим пример записи лога формата ECLF. Пример записи: 149.1xx.120.116 -- smithj [28/OCT/2004:20:27:32-5000] ``GET /Default.htm HTTP/1.1'' 200 1270 ``http:/www.basegroup.ru/'' ''Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.0)''
После того как извлечен с веб-сервера лог-файл и определен его формат, необходимо приступить к предобработке данных. Предобработка данныхИсходные данные, полученные из лога, нуждаются в предобработке. Какую информацию из него можно извлечь?
Для чего необходима предобработка веб-данных? Очистка данных. Набор данных необходимо отфильтровать от записей, генерируемых автоматически совместно с загрузкой страницы. Удаление записей, не отражающих активность пользователя. Веб-боты в автоматическом режиме просматривают множество различных страниц в сети. Их поведение сильно отличается от человеческого, и они не представляют интереса с точки зрения анализа использования веб-ресурсов. Определение каждого отдельного пользователя. Большинство порталов в сети Интернет доступны анонимным пользователям. Можно применять информацию о зарегистрированных пользователях, доступные cookie-файлы для определения каждого пользователя. Идентификация пользовательской сессии. Это означает, что для каждого визита определяются страницы, которые был запрошены и их порядок просмотра. Также пытаются оценить, когда пользователь покинул веб-сайт. Нахождение полного пути. Множество людей используют кнопку "Назад" для возвращения к ранее просмотренной странице. Если это происходит, то браузер отображает страницу, ранее сохраненную в кэше. Это приводит к "дырам" в журнале веб-сервера. Знания о топологии сайта могут быть использованы для восстановления таких пропусков. Рассмотрим пример. Для этого возьмем веб-лог сайта BaseGroup Labs – www.basegroup.ru. Формат – ECLF. Фрагмент используемого лог-файла приведен ниже. Фрагмент веб-лога194.187.204.53 - - [08/Mar/2010:18:35:35 +0300] GET /img/btn_close.gif HTTP/1.1 200 377 http://www.basegroup.ru/solutions/scripts/details/pi_analysis/ Mozilla/5.0 (Windows; U; Windows NT 5.1; ru; rv:1.8.1.20) Gecko/20081217 AdCentriaIM/1.7 Firefox/2.0.0.20 sputnik 2.0.1.41 194.187.204.53 - - [08/Mar/2010:18:35:35 +0300] GET /img/formuls/math_921_c5da77d27189b563b0346a015babea75.png HTTP/1.1 200 1138 http://www.basegroup.ru/solutions/scripts/details/pi_analysis/ Mozilla/5.0 (Windows; U; Windows NT 5.1; ru; rv:1.8.1.20) Gecko/20081217 AdCentriaIM/1.7 Firefox/2.0.0.20 sputnik 2.0.1.41 Как было раннее сказано, лог – это текстовый файл. Но так как данные в него заносятся довольно часто и хранится он на сервере продолжительное время, то его размеры могут достигать нескольких гигабайт. Так как пользователи регулярно посещают сайт, то достаточно будет проанализировать данные за один месяц. В нашем лог-файле возьмем только информацию за март 2010 года. Общее количество записей за указанный период равно 2 725 442. Сразу после импорта данных необходимо привести их к требуемому типу и форматам. Например, значение поля даты-времени в лог-файле записано как [01/Mar/2010:09:47:42 +0300]. С помощью строковых операций и преобразований типов данных можно получить требуемый формат даты. Также из HTTP-запроса необходимо выделить метод, запрашиваемый ресурс и протокол. Очистка и фильтрация данныхВначале необходимо удалить записи, генерируемые совместно с загружаемой страницей. Нас не интересует загрузка файлов с расширениями .gif, .jpeg, .js, .css и им подобные. Все это, по сути, части одной страницы. Но не стоит обобщать этот фильтр на файлы с расширениями .html, .exe, так как информация о них может быть полезной. Такой фильтр организовать несложно с помощью элементарных строковых функций. Например, если подстрока ".gif" присутствует в адресе запрошенного ресурса, то её следует пометить. Выявив строки со всеми другими ненужными расширениями, отфильтровываем записи. Также необходимо провести замену страниц с PHP-запросами. Их можно распознать по знаку вопроса. После применения фильтра в нашем наборе данных осталось 451 559 записей. Таким образом, был отфильтрован 81%. Удаление записей, не отражающих активность пользователейПоисковые машины нуждаются в наиболее актуальной информации, доступной в сети Интернет. Они посылают поисковых агентов и автоматических веб-ботов для выполнения исчерпывающего поиска сайтов. Поведение таких программ на портале сильно отличается от человеческого. Например, бот может запросить все имеющиеся страницы сайта одну за другой. Такие загрузки совершенно не интересны с точки зрения анализа использования веб-ресурсов и могут отрицательно повлиять на точность оценки. Большинство методов исключения ботов, пауков и поисковых агентов из набора данных основаны на обнаружении их имени в поле пользовательского агента. Часто в их имя может быть включен URL или e-mail адрес. Практически это можно реализовать поиском в строке заданных подстрок, помечая записи. В нашем примере 43% записей соответствуют визитам ботов, а 57% – реальным людям (рис. 4).
 Рисунок 4. Количество найденных ботов Далее помеченные записи отфильтровываются. Определение пользователейНа этом шаге главной задачей является определение каждого отдельного пользователя, посетившего сайт. Для этого необходимо использовать информацию из поля "Авторизация". В нашем случае все пользователи сайта были не авторизованы, и в данном поле у всех записей стоит прочерк. Для определения неавторизованных пользователей существует своя методика. Рассмотрим её шаги.
Рассчитанный временной штамп – это прошедшее количество секунд от базовой даты. Определение сессииКаждый определенный пользователь в течение исследуемого периода мог посещать портал несколько раз, и вполне возможно, что с различными целями. Поэтому визиты пользователей необходимо разбить на сессии. Для этого необходимо решить, какой максимальный промежуток времени t может быть между просмотрами отдельных страниц. На рисунке 2 приведен фрагмент данных из примера. Обратим внимание на пользователя 42. 23 марта он посетил 3 страницы, и следующие визиты были им сделаны уже 26 числа. Совершенно очевидно, что у него было две сессии: 23 и 26 марта.
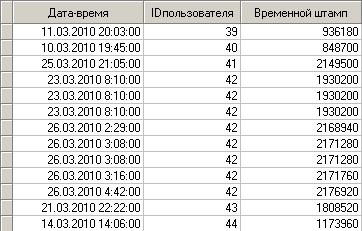 Рисунок 5. Пример пользователя с несколькими сессиями Процедура идентификации каждой отдельной сессии состоит из нескольких шагов.
Далее в зависимости от поставленных задач анализа можно проводить различные трансформации с данными, например, можно помечать сессии по наличию той или иной страницы. Дальнейшие шаги предобработки данныхРассмотренные выше методы предобработки специфичны исключительно для данных веб-логов. Однако это не означает, что сведения уже готовы к использованию и построению моделей. Далее необходимо провести обычные шаги обработки, используемые в KDD, а именно:
Извлечение веб-структурДанное направление рассматривает взаимосвязи между веб-страницами, основываясь на связях между ними. Построенные модели могут быть использованы для категоризации веб-ресурсов, поиска схожих и распознавания авторских сайтов. В зависимости от поставленной задачи структура сайта моделируется с определенным уровнем детализации. В самом простом случае гиперссылки представляют в виде направленного графа: G = (D, L), где D – это набор страниц, узлов или документов; L – набор ссылок. Извлечение веб-структур может быть использовано как подготовительный этап для извлечения веб-контента. Извлечение веб-контентаПоиск знаний в сети Интернет является непростой и трудоемкой задачей. Именно это направление Web Mining решает её. Оно основано на сочетании возможностей информационного поиска, машинного обучения и Data Mining. Кроме того, Web Content Mining подразумевает автоматический поиск и извлечение качественной информации из разнообразных источников Интернета, перегруженных "информационным шумом". Здесь также идет речь о различных средствах кластеризации и аннотировании документов. В этом направлении, в свою очередь, выделяют два подхода: подход, основанный на агентах, и подход, основанный на базах данных. Подход, основанный на агентах (Agent Based Approach), включает такие системы:
Примеры систем интеллектуальных агентов поиска:
Подход, основанный на базах данных (Database Approach), включает системы:
Примеры систем web-запросов:
Анализируется содержание документов: находятся схожие по смыслу слова и их количество. Затем решается задача кластеризации или классификации. Так документы группируются по смысловой близости. Это направление может быть использовано для оптимизации поиска индексированных документов. Общая взаимосвязь между категориями Web Mining и задачами Data Mining изображена на рисунке 6.
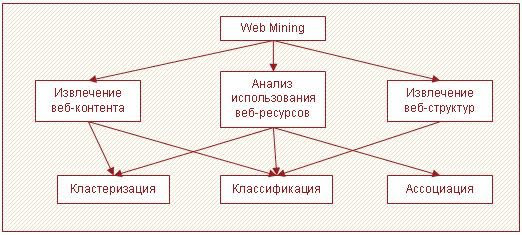 Рисунок 6. Категории Web Mining и задачи Data Mining Методы Web Mining с точки зрения решаемых задач и реализуемых подходовПоиск информацииДля нахождения необходимой информации пользователи обычно пользуются поисковыми ресурсами. При этом часто используются простые запросы по ключевым словам. Результатом выполнения запроса является список страниц, отсортированный по некому индексу релевантности, описывающему степень совпадения результата с запросом. Однако существующие поисковые механизмы обладают недостатками. Основным из них является низкая точность результата, вызванная недостаточным учетом семантических связей и контекста найденных в тексте выражений. Индексация интересующих сегментов сети с использованием интеллектуального анализа данных, применяющего алгоритмы математической лингвистики и обработки естественных языков, является перспективным направлением Web Mining в области поиска информации. Интересный подход описан в статье Anupam Joshi, "Improving Web Search Engine Results Using Clustering". Анализ структуры сегмента сетиЭтот метод заключается в анализе структуры ссылок между различными веб-страницами, внутренними и внешними сайтами в выделенном сетевом сегменте. Появление этого метода было вызвано необходимостью решения задач, возникающих при анализе социальных сетей или специфических областей человеческой деятельности или знаний, например, в анализе цитирования авторов. Результатом такого анализа может служить выявленный набор специфичных страниц следующих типов:
Топология структуры ссылок представляется в виде направленного графа с помеченными узлами в соответствии с их функциональной классификацией и дугами с весами, описывающими, например, частоты переходов по ссылке. Для моделирования топологии веб-ссылок используется несколько алгоритмов, например HITS (Jon M. Kleinberg, "Authoritative sources in hyperlink environment"). Выявление знаний из веб-ресурсовЭта задача пересекается с уже описанной проблемой поиска информации. Только здесь у исследователя уже имеется набор веб-страниц, полученных в результате запроса. Далее требуется произвести их обработку с точки зрения автоматической классификации, составления оглавлений, выявления ключевых слов и общих тем. Выявленные знания могут представляться в виде деревьев, описывающих структуры документов или в виде логических и семантических выражений. Решение части этих проблем предлагает Text Mining - технология автоматического извлечения знаний в больших объемах текстового материала, основанная на сочетании лингвистических, семантических, статистических и машинных обучающихся методик (/go.asp?url=-3D-41-52-17-22-18-3E-34-CB-A3-D6-2C-32-9D-83-9F-88-DA-CF-55-59-6F-C5-A8-73-04-43-10-83-27-69-E9-96-42-55-74-98-06-FA-1B Soumen Chakrabarti "Data mining for hypertext", Helena Ahonen-Myka, "Finding co-occuring text phrases by combining sequence and frequent set discovery") Персонализация информацииПерсонализация веб-пространства - задача по созданию веб-систем, адаптирующих свои возможности (навигация, контент, баннеры и другие рекламные предложения) под пользователя на основании собранной и проанализированной информации о пользовательских предпочтениях. Классическим примером может являться ресурс /go.asp?url=-3D-41-52-17-22-18-3E-34-CB-A3-D6-20-3A-9B-98-80-93-80-C9-48-1A-32-9C на котором один раз заказав дорогую книгу в твердом переплете, пользователь начинает регулярно получать предложения о покупке подарочных изданий по схожей тематике. Другой пример - на основании анализа корзин заказов пользователя ему предлагаются товары, которые он никогда не заказывал, но которые входят в корзины других покупателей, схожих с ним по транзакционному поведению. Для анализа информации о пользователе следует в наименьшей степени использовать декларируемую о себе информацию, а скорее основываться на стойких шаблонах его "поведения" в сети - последовательности кликов внутри ресурса, переходах на другие под-ресурсы, периодах сетевой активности, осуществляемых покупках и т.д. См. B. Masand, Redwood, "Web Usage Analysis and User Profiling", Miha Gr?ar, "User profiling: Web usage mining". Поиск шаблонов в поведении пользователейЭта задача связана с предыдущей, но ее целью является не адаптация ресурса к предпочтениям индивидуальных пользователей, а поиск закономерностей в шаблонах взаимодействия пользователя с веб-ресурсом с целью прогнозирования его последующих действий. Анализируемые действия пользователей могут включать не только переходы по ссылкам, но и отправку форм, прокрутку страниц, добавление в избранные страницы и т.д. Найденные шаблоны используются в дальнейшем для оптимизации структуры сайта, изучения целевой аудитории и для прямого маркетинга. Разработано множество подходов к решению задачи по выявлению знаний из шаблонов навигации пользователей (Jose Borges и Mark Levene "Data Mining of User Navigation Patterns", A. G. Buechner "Navigation Pattern Discovery from Internet Data"). С точки зрения применения алгоритмов интеллектуального анализа данных при поиске шаблонов пользовательского поведения чаще всего используются следующие методики:
Особенно интересен подход кластеризации последовательностей - поиск групп пользователей со схожими последовательностями действий. На первом этапе в этом подходе выделяются последовательности классифицированных действий пользователя, например, в рамках одной сессии. Затем подсчитываются частоты переходов между различными действиями для составления Марковской цепи заданного порядка. На заключительном этапе полученные Марковские цепи кластеризуются для выявления групп с похожими частотами переходов. Для прогнозирования следующего действия пользователя сначала на основании истории его действий в рамках сессии определяется группа, к которой он принадлежит с наибольшей вероятностью. Затем определяется действие, которое выполняется с наибольшей вероятностью в этой группе с учетом последних действий данного пользователя. Для реализации такого анализа можно, например, использовать алгоритм Microsoft Sequential Clustering, входящий в Microsoft Analysis Services 2005/2008. Недостатком алгоритма Microsoft является то, что до настоящего времени реализован алгоритм, использующий Марковские цепи только первого порядка. В качестве примера применения метода анализа последовательности действий можно привести задачу по оптимизации рубрикации одного книжного интернет-магазина, проведенную компанией spellabs. Была выявлена группа, состоящая из пользователей, переходящих долгими путями по ссылкам на книги из разных рубрик и заказывающих в конечном итоге "изотерическую" литературу , до этого отдельно не выделенную в рубрику. Так была выявлена неучтенная целевая аудитория и оптимизирована структура сайта. В бизнес-аналитике Web Mining решает следующие задачи:
Список источников информации
По материалам сайта: Зверніть увагу на додаткові посиланняГоловний розділСторінки, близькі за змістомзагрузка...
|
Сторінки, близькі за змістом
|
|
Copyright © 2008—2026 Портал Знань.
При використанні матеріалів посилання, для інтернет-ресурсів — гіперпосилання, на Znannya.org обов'язкове.
Зв'язок
|
НТУУ "КПІ" Інженерія програмного забезпечення КПІ Лабораторія СЕТ |
|
 Керування знаннями
Керування знаннями

