
|
Data Mining
ADO в Delphi AJAX Android C++ CakePHP CMS COM CSS Delphi Flash Flex HTML Internet Java JavaScript MySQL PHP RIA SCORM Silverlight SQL UML XML Бази даних Веб-розробка Генетичні алгоритми ГІС Гітара Дизайн Економіка Інтелектуальні СДН Колір Масаж Математика Медицина Музика Нечітка логіка ООП Патерни Подання знань Розкрутка сайту, SEO САПР Сесії в PHP Системне програмування Системний аналіз Тестологія Тестування ПЗ Фреймворки Штучний інтелект
|
Data MiningОглавление1. Основные понятия 1.1 Свойства обнаруживаемых знаний 2. Задачи DataMining
2.1 Классификация (Classification)
3. Сферы применения DataMining
4.1 Классификация методов
5. Инструменты DataMining Основные понятияOLAP-системы предоставляют аналитику средства проверки гипотез при анализе данных, то есть основной задачей аналитика является генерация гипотез, которую он решает ее, основываясь на своих знаниях и опыте. Однако знания есть не только у человека, но и у накопленных данных, которые подвергаются анализу. Такие знания содержатся в огромной объеме информации, которую человек не в силах исследовать самостоятельно. В связи с этим существует вероятность пропустить гипотезы, которые могут принести значительную выгоду. Для обнаружения «скрытых» знаний применяется специальные методы автоматического анализа, при помощи которых приходиться практически добывать знания из «завалов» информации. За этим направлением закрепился термин «добыча данных (DataMining)» или «интеллектуальный анализ данных». Существует множество определений DataMining, которые друг друга дополняют. Вот некоторые из них:
Свойства обнаруживаемых знанийРассмотрим свойства обнаруживаемых знаний.
В DataMining для представления полученных знаний служат модели. Виды моделей зависят от методов их создания. Наиболее распространенными являются: правила, деревья решений, кластеры и математические функции. Задачи DataMiningНапомним, что в основу технологии DataMining положена концепция шаблонов, представляющих собой закономерности. В результате обнаружения этих, скрытых от невооруженного глаза закономерностей решаются задачи DataMining. Различным типам закономерностей, которые могут быть выражены в форме, понятной человеку, соответствуют определенные задачи DataMining. Единого мнения относительно того, какие задачи следует относить к DataMining, нет. Большинство авторитетных источников перечисляют следующие: классификация, кластеризация, прогнозирование, ассоциация, визуализация, анализ и обнаружение отклонений, оценивание, анализ связей, подведение итогов. Цель описания, которое следует ниже, - дать общее представление о задачах DataMining, сравнить некоторые из них, а также представить некоторые методы, с помощью которых эти задачи решаются. Наиболее распространенные задачи DataMining - классификация,кластеризация, ассоциация, прогнозирование и визуализация. Таким образом, задачи подразделяются по типам производимой информации, это наиболее общая классификация задач DataMining. Классификация (Classification)Задача разбиения множества объектов или наблюдений на априорно заданные группы, называемые классами, внутри каждой из которых они предполагаются похожими друг на друга, имеющими примерно одинаковые свойства и признаки. При этом решение получается на основе анализа значений атрибутов (признаков). Классификация является одной из важнейших задач DataMining. Она применяется в маркетинге при оценке кредитоспособности заемщиков, определении лояльности клиентов, распознавании образов, медицинской диагностике и многих других приложениях. Если аналитику известны свойства объектов каждого класса, то когда новое наблюдение относится к определенному классу, данные свойства автоматически распространяются и на него. Если число классов ограничено двумя, то имеет место бинарная классификация, к которой могут быть сведены многие более сложные задачи. Например, вместо определения таких степеней кредитного риска, как «Высокий», «Средний» или «Низкий», можно использовать всего две - «Выдать» или «Отказать». Для классификации в DataMining используется множество различных моделей: нейронные сети, деревья решений, машины опорных векторов, метод k-ближайших соседей, алгоритмы покрытия и др., при построении которых применяется обучение с учителем, когда выходная переменная (метка класса) задана для каждого наблюдения. Формально классификация производится на основе разбиения пространства признаков на области, в пределах каждой из которых многомерные векторы рассматриваются как идентичные. Иными словами, если объект попал в область пространства, ассоциированную с определенным классом, он к нему и относится. Кластеризация (Clustering)Краткое описание. Кластеризация является логическим продолжением идеи классификации. Это задача более сложная, особенность кластеризации заключается в том, что классы объектов изначально не предопределены. Результатом кластеризации является разбиение объектов на группы. Пример метода решения задачи кластеризации: обучение "без учителя" особого вида нейронных сетей - самоорганизующихся карт Кохонена. Ассоциация (Associations)Краткое описание. В ходе решения задачи поиска ассоциативных правил отыскиваются закономерности между связанными событиями в наборе данных. Отличие ассоциации от двух предыдущих задач DataMining: поиск закономерностей осуществляется не на основе свойств анализируемого объекта, а между несколькими событиями, которые происходят одновременно. Наиболее известный алгоритм решения задачи поиска ассоциативных правил – алгоритм Apriori. Последовательность (Sequence) или последовательная ассоциация (sequentialassociation)Краткое описание. Последовательность позволяет найти временные закономерности между транзакциями. Задача последовательности подобна ассоциации, но ее целью является установление закономерностей не между одновременно наступающими событиями, а между событиями, связанными во времени (т.е. происходящими с некоторым определенным интервалом во времени). Другими словами, последовательность определяется высокой вероятностью цепочки связанных во времени событий. Фактически, ассоциация является частным случаем последовательности с временным лагом, равным нулю. Эту задачу DataMining также называют задачей нахождения последовательных шаблонов (sequentialpattern). Правило последовательности: после события X через определенное время произойдет событие Y. Пример. После покупки квартиры жильцы в 60% случаев в течение двух недель приобретают холодильник, а в течение двух месяцев в 50% случаев приобретается телевизор. Решение данной задачи широко применяется в маркетинге и менеджменте, например, при управлении циклом работы с клиентом (CustomerLifecycleManagement). Регрессия, прогнозирование (Forecasting)Краткое описание. В результате решения задачи прогнозирования на основе особенностей исторических данных оцениваются пропущенные или же будущие значения целевых численных показателей. Для решения таких задач широко применяются методы математической статистики, нейронные сети и др. Дополнительные задачиОпределение отклонений или выбросов (DeviationDetection), анализ отклонений или выбросов Краткое описание. Цель решения данной задачи - обнаружение и анализ данных, наиболее отличающихся от общего множества данных, выявление так называемых нехарактерных шаблонов. Оценивание (Estimation) Задача оценивания сводится к предсказанию непрерывных значений признака. Анализ связей (LinkAnalysis) Задача нахождения зависимостей в наборе данных. Визуализация (Visualization, GraphMining) В результате визуализации создается графический образ анализируемых данных. Для решения задачи визуализации используются графические методы, показывающие наличие закономерностей в данных. Пример методов визуализации - представление данных в 2-D и 3-D измерениях. Подведение итогов (Summarization) Задача, цель которой - описание конкретных групп объектов из анализируемого набора данных. Достаточно близким к вышеупомянутой классификации является подразделение задач DataMining на следующие: исследования и открытия, прогнозирования и классификации, объяснения и описания. Автоматическое исследование и открытие (свободный поиск) Пример задачи: обнаружение новых сегментов рынка. Для решения данного класса задач используются методы кластерного анализа. Прогнозирование и классификация Пример задачи: предсказание роста объемов продаж на основе текущих значений. Методы: регрессия, нейронные сети, генетические алгоритмы, деревья решений. Задачи классификации и прогнозирования составляют группу так называемого индуктивного моделирования, в результате которого обеспечивается изучение анализируемого объекта или системы. В процессе решения этих задач на основе набора данных разрабатывается общая модель или гипотеза. Объяснение и описание Пример задачи: характеристика клиентов по демографическим данным и историям покупок. Методы: деревья решения, системы правил, правила ассоциации, анализ связей. Если доход клиента больше, чем 50 условных единиц, и его возраст - более 30 лет, тогда класс клиента - первый. Сравнение кластеризации и классификации
Сферы применения DataMiningСледует отметить, что на сегодняшний день наибольшее распространение технология DataMining получила при решении бизнес-задач. Возможно, причина в том, что именно в этом направлении отдача от использования инструментов DataMining может составлять, по некоторым источникам, до 1000% и затраты на ее внедрение могут достаточно быстро окупиться. Мы будем рассматривать четыре основные сферы применения технологии DataMining подробно: наука, бизнес, исследования для правительства и Web-направление. Применение DataMining для решения бизнес-задач. Основные направления: банковскоедело, финансы, страхование, CRM, производство, телекоммуникации, электроннаякоммерция, маркетинг, фондовый рынок и другие.
Применение DataMining для решения задач государственного уровня. Основныенаправления: поиск лиц, уклоняющихся от налогов; средства в борьбе с терроризмом. Применение DataMining для научных исследований. Основные направления: медицина,биология, молекулярная генетика и генная инженерия, биоинформатика, астрономия,прикладная химия, исследования, касающиеся наркотической зависимости, и другие. Применение DataMining для решения Web-задач. Основные направления: поисковыемашины (searchengines), счетчики и другие. Электронная коммерция В сфере электронной коммерции DataMining применяется для формирования рекомендательных систем и решения задач классификации посетителей Web-сайтов. Такая классификация позволяет компаниям выявлять определенные группы клиентов и проводить маркетинговую политику в соответствии с обнаруженными интересами и потребностями клиентов. Технология DataMining для электронной коммерции тесно связана с технологией WebMining. Основные задачи DataMining в промышленном производстве:
Маркетинг В сфере маркетинга DataMining находит очень широкое применение. Основные вопросы маркетинга "Что продается?", "Как продается?", "Кто является потребителем?" В лекции, посвященной задачам классификации и кластеризации, подробно описано использование кластерного анализа для решения задач маркетинга, как, например, сегментация потребителей. Другой распространенный набор методов для решения задач маркетинга - методы и алгоритмы поиска ассоциативных правил. Также успешно здесь используется поиск временных закономерностей. Розничная торговля В сфере розничной торговли, как и в маркетинге, применяются:
Фондовый рынок Вот список задач фондового рынка, которые можно решать при помощи технологии Data Mining :
Кроме описанных выше сфер деятельности, технология DataMining может применяться в самых разнообразных областях бизнеса, где есть необходимость в анализе данных и накоплен некоторый объем ретроспективной информации. Применение DataMining в CRM
CRM (CustomerRelationshipManagement) - управление отношениями с клиентами. При совместном использовании этих технологий добыча знаний совмещается с "добычей денег" из данных о клиентах. Важным аспектом в работе отделов маркетинга и отдела продаж является составление целостного представления о клиентах, информация об их особенностях, характеристиках, структуре клиентской базы. В CRM используется так называемое профилирование клиентов, дающее полное представление всей необходимой информации о клиентах. Профилирование клиентов включает следующие компоненты: сегментация клиентов, прибыльность клиентов, удержание клиентов, анализ реакции клиентов. Каждый из этих компонентов может исследоваться при помощи DataMining, а анализ их в совокупности, как компонентов профилирования, в результате может дать те знания, которые из каждой отдельной характеристики получить невозможно. WebMining WebMining можно перевести как "добыча данных в Web". WebIntelligence или Web. Интеллект готов "открыть новую главу" в стремительном развитии электронного бизнеса. Способность определять интересы и предпочтения каждого посетителя, наблюдая за его поведением, является серьезным и критичным преимуществом конкурентной борьбы на рынке электронной коммерции. Системы WebMining могут ответить на многие вопросы, например, кто из посетителей является потенциальным клиентом Web-магазина, какая группа клиентов Web-магазина приносит наибольший доход, каковы интересы определенного посетителя или группы посетителей. МетодыКлассификация методовРазличают две группы методов:
Недостаток такой классификации: и статистические, и кибернетические алгоритмы тем или иным образом опираются на сопоставление статистического опыта с результатами мониторинга текущей ситуации. Преимуществом такой классификации является ее удобство для интерпретации - она используется при описании математических средств современного подхода к извлечению знаний из массивов исходных наблюдений (оперативных и ретроспективных), т.е. в задачах Data Mining. Рассмотрим подробнее представленные выше группы. Статистические методы Data mining В эти методы представляют собой четыре взаимосвязанных раздела:
Арсенал статистических методов Data Mining классифицирован на четыре группы методов:
Кибернетические методы Data Mining Второе направление Data Mining - это множество подходов, объединенных идеей компьютерной математики и использования теории искусственного интеллекта. К этой группе относятся такие методы:
Далее рассмотрим некоторые из представленных методов. Кластерный анализЦель кластеризации - поиск существующих структур. Кластеризация является описательной процедурой, она не делает никаких статистических выводов, но дает возможность провести разведочный анализ и изучить "структуру данных". Само понятие "кластер" определено неоднозначно: в каждом исследовании свои "кластеры". Переводится понятие кластер (cluster) как "скопление", "гроздь". Кластер можно охарактеризовать как группу объектов, имеющих общие свойства. Характеристиками кластера можно назвать два признака:
Вопрос, задаваемый аналитиками при решении многих задач, состоит в том, как организовать данные в наглядные структуры, т.е. развернуть таксономии. Наибольшее применение кластеризация первоначально получила в таких науках как биология, антропология, психология. Для решения экономических задач кластеризация длительное время мало использовалась из-за специфики экономических данных и явлений. Кластеры могут быть непересекающимися, или эксклюзивными (non-overlapping, exclusive), и пересекающимися (overlapping) [22]. Следует отметить, что в результате применения различных методов кластерного анализа могут быть получены кластеры различной формы. Например, возможны кластеры "цепочного" типа, когда кластеры представлены длинными "цепочками", кластеры удлиненной формы и т.д., а некоторые методы могут создавать кластеры произвольной формы. Различные методы могут стремиться создавать кластеры определенных размеров (например, малых или крупных) либо предполагать в наборе данных наличие кластеров различного размера. Некоторые методы кластерного анализа особенно чувствительны к шумам или выбросам, другие - менее. В результате применения различных методов кластеризации могут быть получены неодинаковые результаты, это нормально и является особенностью работы того или иного алгоритма. Данные особенности следует учитывать при выборе метода кластеризации. Приведем краткую характеристику подходов к кластеризации. Алгоритмы, основанные на разделении данных (Partitioningalgorithms), в т.ч. итеративные:
Методы, основанные на концентрации объектов (Density-basedmethods):
Грид-методы (Grid-based methods):
Модельные методы (Model-based):
Методы кластерного анализа. Итеративные методы. При большом количестве наблюдений иерархические методы кластерного анализа не пригодны. В таких случаях используют неиерархические методы, основанные на разделении, которые представляют собой итеративные методы дробления исходной совокупности. В процессе деления новые кластеры формируются до тех пор, пока не будет выполнено правило остановки. Такая неиерархическая кластеризация состоит в разделении набора данных на определенное количество отдельных кластеров. Существует два подхода. Первый заключается в определении границ кластеров как наиболее плотных участков в многомерном пространстве исходных данных, т.е. определение кластера там, где имеется большое "сгущение точек". Второй подход заключается в минимизации меры различия объектов Алгоритм k-средних (k-means)Наиболее распространен среди неиерархических методов алгоритм k-средних, также называемый быстрым кластерным анализом. Полное описание алгоритма можно найти в работе Хартигана и Вонга (HartiganandWong, 1978). В отличие от иерархических методов, которые не требуют предварительных предположений относительно числа кластеров, для возможности использования этого метода необходимо иметь гипотезу о наиболее вероятном количестве кластеров. Алгоритм k-средних строит k кластеров, расположенных на возможно больших расстояниях друг от друга. Основной тип задач, которые решает алгоритм k-средних, - наличие предположений (гипотез) относительно числа кластеров, при этом они должны быть различны настолько, насколько это возможно. Выбор числа k может базироваться на результатах предшествующих исследований, теоретических соображениях или интуиции. Общая идея алгоритма: заданное фиксированное число k кластеров наблюдения сопоставляются кластерам так, что средние в кластере (для всех переменных) максимально возможно отличаются друг от друга. Описание алгоритма 1. Первоначальное распределение объектов по кластерам.
Выбор начальныхцентроидов может осуществляться следующим образом:
В результате каждый объект назначен определенному кластеру. 2. Итеративный процесс. Вычисляются центры кластеров, которыми затем и далее считаются покоординатные средние кластеров. Объекты опять перераспределяются. Процесс вычисления центров и перераспределения объектов продолжается до тех пор, пока не выполнено одно из условий:
На рисунке приведен пример работы алгоритма k-средних для k, равного двум. Пример работы алгоритма k-средних (k=2)
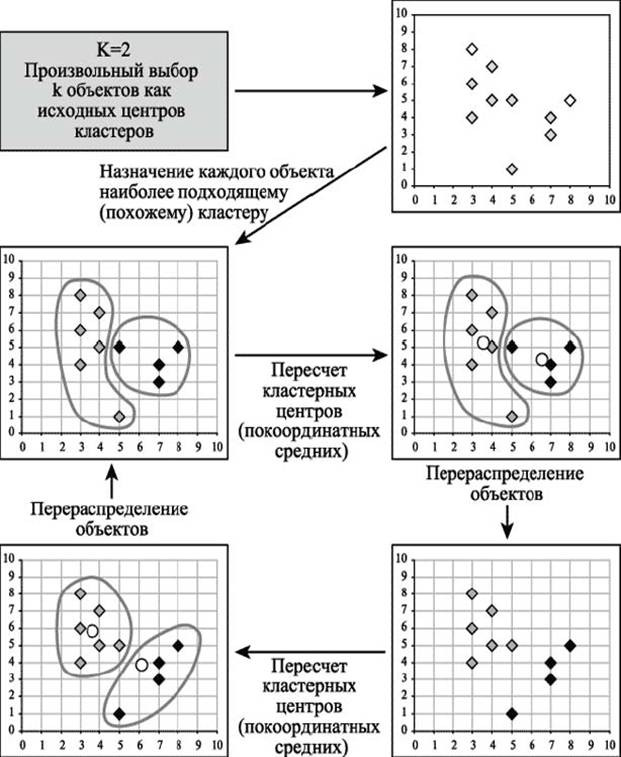 Выбор числа кластеров является сложным вопросом. Если нет предположений относительно этого числа, рекомендуют создать 2 кластера, затем 3, 4, 5 и т.д., сравнивая полученные результаты. Проверка качества кластеризации После получений результатов кластерного анализа методом k-средних следует проверить правильность кластеризации (т.е. оценить, насколько кластеры отличаются друг от друга). Для этого рассчитываются средние значения для каждого кластера. При хорошей кластеризации должны быть получены сильно отличающиеся средние для всех измерений или хотя бы большей их части. Достоинства алгоритма k-средних:
Недостатки алгоритма k-средних:
Возможным решением этой проблемы является использование модификации алгоритма -алгоритм k-медианы:
Байесовские сетиВ теории вероятности понятие информационной зависимости моделируется посредством условной зависимости (или строго: отсутствием условной независимости), которая описывает, как наша уверенность в исходе некоего события меняется при получении нового знания о фактах, при условии, что нам был уже известен некоторый набор других фактов. Удобно и интуитивно понятно представлять зависимости между элементами посредством направленного пути, соединяющего эти элементы в графе. Если зависимость между элементами x и y не является непосредственной и осуществляется посредством третьего элемента z, то логично ожидать, что на пути между x и y будет находиться элемент z. Такие узлы-посредники будут «отсекать» зависимость между x и y, т.е. моделировать ситуацию условной независимости между ними при известном значении непосредственных факторов влияния. Такими языками моделирования являются байесовские сети, которые служат для описания условных зависимостей между понятиями некой предметной области. Байесовские сети - это графические структуры для представления вероятностных отношений между большим количеством переменных и для осуществления вероятностного вывода на основе этих переменных. "Наивная" (байесовская) классификация - достаточно прозрачный и понятный метод классификации."Наивной" она называется потому, что исходит из предположения о взаимной независимости признаков. Свойства классификации:
Различают два основных сценария применения байесовских сетей: 1. Описательный анализ. Предметная область отображается в виде графа, узлы которого представляют понятия, а направленные дуги, отображаемые стрелками, иллюстрируют непосредственные зависимости между этими понятиями. Связь между понятиями x и y означает: знание значения x помогает сделать более обоснованное предположение о значении y. Отсутствие непосредственной связи между понятиями моделирует условную независимость между ними при известных значениях некоторого набора «разделяющих» понятий. Например, размер обуви ребенка, очевидно, связан с умением ребенка читать через возраст. Так, больший размер обуви дает большую уверенность, что ребенок уже читает, но если нам уже известен возраст, то знание размера обуви уже не даст нам дополнительной информации о способности ребенка к чтению.
 В качестве другого, противоположного, примера рассмотрим такие изначально несвязанные факторы как курение и простуда. Но если нам известен симптом, например, что человек страдает по утрам кашлем, то знание того, что человек не курит, повышает нашу уверенность того, что человек простужен.
 2. Классификация и прогнозирование. Байесовская сеть, допуская условную независимость ряда понятий, позволяет уменьшить число параметров совместного распределения, делая возможным их доверительную оценку на имеющихся объемах данных. Так, при 10 переменных, каждая из которых может принимать 10 значений, число параметров совместного распределения – 10 миллиардов - 1. Если допустить, что между этими переменными друг от друга зависят только 2 переменные, то число параметров становится 8*(10-1) + (10*10-1) = 171. Имея реалистичную по вычислительным ресурсам модель совместного распределения, неизвестное значение какого-либо понятия мы можем прогнозировать как, например, наиболее вероятное значение этого понятия при известных значениях других понятий. Отмечают такие достоинства байесовских сетей как метода DataMining:
Наивно-байесовский подход имеет следующие недостатки:
Искусственные нейронные сетиИскуственные нейронные сети(далее нейронные сети) могут быть синхронные и асинхронные. В синхронных нейронных сетях в каждый момент времени свое состояние меняет лишь один нейрон. В асинхронных - состояние меняется сразу у целой группы нейронов, как правило, у всего слоя. Можно выделить две базовые архитектуры - слоистые и полносвязные сети. Ключевым в слоистых сетях является понятие слоя. Слой - один или несколько нейронов, на входы которых подается один и тот же общий сигнал. Слоистые нейронные сети - нейронные сети, в которых нейроны разбиты на отдельные группы (слои) так, что обработка информации осуществляется послойно. В слоистых сетях нейроны i-го слоя получают входные сигналы, преобразуют их и через точки ветвления передают нейронам (i+1) слоя. И так до k-го слоя, который выдает выходные сигналы для интерпретатора и пользователя. Число нейронов в каждом слое не связано с количеством нейронов в других слоях, может быть произвольным. В рамках одного слоя данные обрабатываются параллельно, а в масштабах всей сети обработка ведется последовательно - от слоя к слою. К слоистым нейронным сетям относятся, например, многослойные персептроны, сети радиальных базисных функций, когнитрон, некогнитрон, сети ассоциативной памяти. Однако сигнал не всегда подается на все нейроны слоя. В когнитроне, например, каждый нейрон текущего слоя получает сигналы только от близких ему нейронов предыдущего слоя.
Слоистые сети, в свою очередь, могут быть однослойными и многослойными. В многослойной сети первый слой называется входным, последующие - внутренними или скрытыми, последний слой - выходным. Таким образом, промежуточные слои - это все слои в многослойной нейронной сети, кроме входного и выходного. Входной слой сети реализует связь с входными данными, выходной - с выходными. Таким образом, нейроны могут быть входными, выходными и скрытыми. Входной слой организован из входных нейронов (inputneuron), которые получают данные и распространяют их на входы нейронов скрытого слоя сети. Скрытый нейрон (hiddenneuron) - это нейрон, находящийся в скрытом слое нейронной сети. Выходные нейроны (outputneuron), из которых организован выходной слой сети, выдает результаты работы нейронной сети. В полносвязных сетях каждый нейрон передает свой выходной сигнал остальным нейронам, включая самого себя. Выходными сигналами сети могут быть все или некоторые выходные сигналы нейронов после нескольких тактов функционирования сети. Все входные сигналы подаются всем нейронам. Обучение нейронных сетей Перед использованием нейронной сети ее необходимо обучить. Процесс обучения нейронной сети заключается в подстройке ее внутренних параметров под конкретную задачу. Алгоритм работы нейронной сети является итеративным, его шаги называют эпохами или циклами. Эпоха - одна итерация в процессе обучения, включающая предъявление всех примеров из обучающего множества и, возможно, проверку качества обучения на контрольном множестве. Процесс обучения осуществляется на обучающей выборке. Обучающая выборка включает входные значения и соответствующие им выходные значения набора данных. В ходе обучения нейронная сеть находит некие зависимости выходных полей от входных. Таким образом, перед нами ставится вопрос - какие входные поля (признаки) нам необходимо использовать. Первоначально выбор осуществляется эвристически, далее количество входов может быть изменено. Сложность может вызвать вопрос о количестве наблюдений в наборе данных. И хотя существуют некие правила, описывающие связь между необходимым количеством наблюдений и размером сети, их верность не доказана. Количество необходимых наблюдений зависит от сложности решаемой задачи. При увеличении количества признаков количество наблюдений возрастает нелинейно, эта проблема носит название "проклятие размерности". При недостаточном количестве данных рекомендуется использовать линейную модель. Аналитик должен определить количество слоев в сети и количество нейронов в каждом слое. Далее необходимо назначить такие значения весов и смещений, которые смогут минимизировать ошибку решения. Веса и смещения автоматически настраиваются таким образом, чтобы минимизировать разность между желаемым и полученным на выходе сигналами, которая называется ошибка обучения. Ошибка обучения для построенной нейронной сети вычисляется путем сравнения выходных и целевых (желаемых) значений. Из полученных разностей формируется функция ошибок. Функция ошибок - это целевая функция, требующая минимизации в процессе управляемого обучения нейронной сети. С помощью функции ошибок можно оценить качество работы нейронной сети во время обучения. Например, часто используется сумма квадратов ошибок. От качества обучения нейронной сети зависит ее способность решать поставленные передтней задачи. Переобучение нейронной сети При обучении нейронных сетей часто возникает серьезная трудность, называемая проблемой переобучения (overfitting). Переобучение, или чрезмерно близкая подгонка - излишне точное соответствие нейронной сети конкретному набору обучающих примеров, при котором сеть теряет способность к обобщению. Переобучение возникает в случае слишком долгого обучения, недостаточного числа обучающих примеров или переусложненной структуры нейронной сети. Переобучение связано с тем, что выбор обучающего (тренировочного) множества является случайным. С первых шагов обучения происходит уменьшение ошибки. На последующих шагах с целью уменьшения ошибки (целевой функции) параметры подстраиваются под особенности обучающего множества. Однако при этом происходит "подстройка" не под общие закономерности ряда, а под особенности его части - обучающего подмножества. При этом точность прогноза уменьшается. Один из вариантов борьбы с переобучением сети - деление обучающей выборки на два множества (обучающее и тестовое). На обучающем множестве происходит обучение нейронной сети. На тестовом множестве осуществляется проверка построенной модели. Эти множества не должны пересекаться. С каждым шагом параметры модели изменяются, однако постоянное уменьшение значения целевой функции происходит именно на обучающем множестве. При разбиении множества на два мы можем наблюдать изменение ошибки прогноза на тестовом множестве параллельно с наблюдениями над обучающим множеством. Какое-то количество шагов ошибки прогноза уменьшается на обоих множествах. Однако на определенном шаге ошибка на тестовом множестве начинает возрастать, при этом ошибка на обучающем множестве продолжает уменьшаться. Этот момент считается началом переобучения Инструменты DataMiningРазработкой в секторе DataMining всемирного рынка программного обеспечения заняты как всемирно известные лидеры, так и новые развивающиеся компании. Инструменты DataMining могут быть представлены либо как самостоятельное приложение, либо как дополнения к основному продукту. Последний вариант реализуется многими лидерами рынка программного обеспечения. Так, уже стало традицией, что разработчики универсальных статистических пакетов, вдополнение к традиционным методам статистического анализа, включают в пакет определенный набор методов DataMining. Этотакиепакетыкак SPSS (SPSS, Clementine), Statistica (StatSoft), SAS Institute (SAS Enterprise Miner). Некоторые разработчики OLAP- решений также предлагают набор методов DataMining, например, семейство продуктов Cognos. Есть поставщики, включающие DataMining решения в функциональность СУБД: это Microsoft (MicrosoftSQLServer), Oracle, IBM (IBMIntelligentMinerforData). Список литературы
По материалам сайта: Зверніть увагу на додаткові посиланняГоловний розділСторінки, близькі за змістомзагрузка...
|
Сторінки, близькі за змістом
|
|
Copyright © 2008—2026 Портал Знань.
При використанні матеріалів посилання, для інтернет-ресурсів — гіперпосилання, на Znannya.org обов'язкове.
Зв'язок
|
НТУУ "КПІ" Інженерія програмного забезпечення КПІ Лабораторія СЕТ |
|
 Керування знаннями
Керування знаннями DataMining – это процесс обнаружения в базах данных нетривиальных и практически полезных закономерностей. (BaseGroup)
DataMining – это процесс обнаружения в базах данных нетривиальных и практически полезных закономерностей. (BaseGroup) Одно из наиболее перспективных направлений применения DataMining – использование данной технологии в аналитическом CRM.
Одно из наиболее перспективных направлений применения DataMining – использование данной технологии в аналитическом CRM.

